
物体检测领域(Object Detection)领域是计算机视觉的经典问题,其目标是在输入图像中寻找特定类别的物体,并使用矩形框将物体包括在内,并预测出该框的类别。深度学习在物体检测领域已经取得了相比于传统视觉方法质的提升,其中很重要原因就是单阶段检测方法(One-Stage Method)和两阶段检测方法(Two-Stage Method)的出现,本篇博客将就物体检测Two Stage检测经典方法Faster RCNN做一些简单的总结,结合一些源码给出个人的理解。
1. RCNN前作慢的原因
在经过RCNN,Fast-RCNN以后,RCNN系列基本确定了以Region Proposal为网络预处理获得提名区域,后对提名的区域使用深度网络进行提取,最终分类的方法作为基本框架。回顾faster-RCNN的前作可以发现,最开始的RCNN速度非常慢,原因有以下几点:
- 使用Selective Search作为Region Proposal的算法:这个算法本身非常慢,而且需要把所有SS产生的ROI全部存储在磁盘上,无论读取还是写入都非常耗时,而且算法效果也不是非常好。
- 将产生的2000+个ROI的图像输入网络(最主要原因)相当于每forward一张图像,就需要forward两千多次卷积网络,非常耗时。
- 最后使用SVM作为判别器:这里不是说SVM慢,而是训练以后不能在同一个网络中实现输出,这些都是额外的开销。
2. Fast-RCNN的改进
Fast-RCNN针对后两点做了改进:
- 使用借鉴SPPnet中的Pyramid Feature的思想,取
空间金字塔特征的一个特例——ROI Pooling作为特征提取,这样使得单张图像的特征提取只需要使用一张图像只需要经过网络一次生成特征图,后将推荐的区域映射到Feature Map中提取map,通过ROI Pooling的方式可以提取到多个候选框的特征。 - 针对上面的第三点,Fast-RCNN通过使用FC层的方式代替SVM,实现了除了候选区域推荐以外的步骤的end2end
当然已经解决了后面两点,接下来就是要把同样很耗时的Selective Search使用网络代替,实现真正意义上的end2end网络。
3. Faster-RCNN

Faster-RCNN能够比Fast更快的原因是使用了一个区域提名网络(Region Proposal Network, RPN)代替SS来做候选框推荐,这种网络能够提取出质量更高,数量更少的候选框。而且把Region Proposal的步骤合并到网络中来,使网络更加end2end。因此FasterRCNN的核心是RPN。能够看出来,Faster-RCNN使用RPN做特征推荐,使用Fast-RCNN作为特征提取器,后面的是和Fast-RCNN是完全一致的。
候选区域推荐网络(RPN)
既然RPN这么重要,那么,RPN是一个什么结构呢,这里我们先来看一下RPN网络的真面目:(这个图是基于VGG的,图片输入size是224,但是实际中实现中一般使用更大的输入图像,如短边600或短边800,这里和ImageNet输入图像大小相同,只是为了理解)
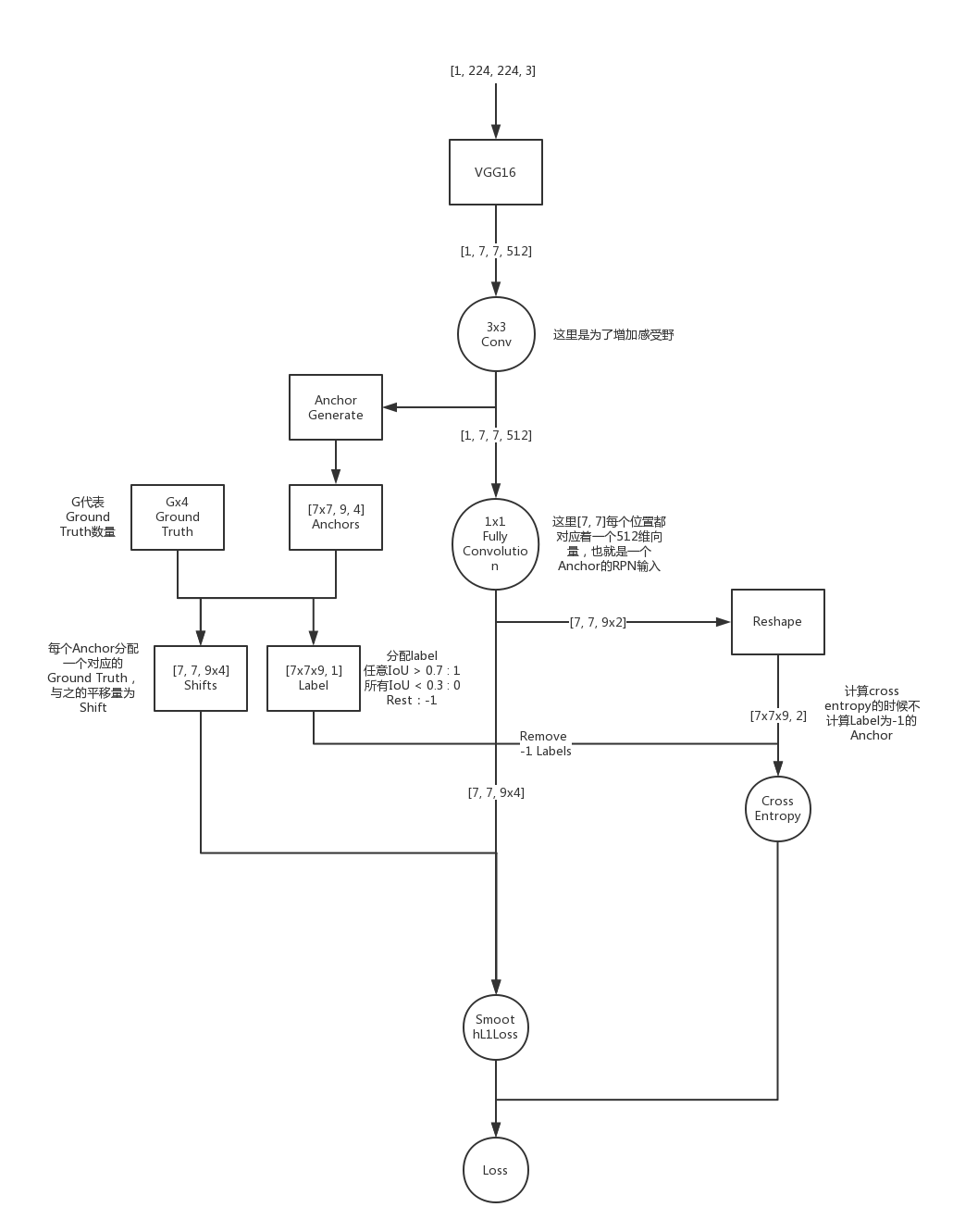

简单来说RPN是目的就是:通过原图像先使用分类网络(VGG,ResNet,ZFNet等)做特征提取,最后生成候选框,再对候选框进行修正。
由于后面的网络已经有了BBox回归,所以我们不需要生成非常精细的候选框,只需要把精修的任务交给后面就行了,为了速度更快的生成这些粗略的候选框,作者使用了一种叫做Anchor的机制:
假设我们使用VGG的某一层Pool作为特征提取层,特征图大小为[N, M, C],其中C为通道,如上图就是M=51,N=39, 如果是使用VGG的输入224的图像,将会变成[14, 14, 512]的特征图(上面的图有一些失误,其实在实现中vgg去掉了最后一个maxpooling,output_stride=16,所以上面的特征图大小应该是14),按照以下方法生成Anchor:
- 将图片通过VGG网络,生成[N, M, C]的特征图
- 在特征图上做3x3的卷积,使之产生一个[1x1xC]的向量,这里是为了增加感受野,作为接下来输入全连接层的输入
- 把特征图上的每一个坐标[i, j]的中心都映射回原图像(如vgg pool5就需要把Feature Map坐标x32)坐标[i’, j’]以这个点为中心构造以长宽比为1:1, 1:2, 2:1,面积为$128^2, 256^2, 512^2$三种面积的矩形9个(当然可以这里面积是一个超参数,总之生成k个候选框,这里k=9),到此我们总共生成了N*M*K个Anchor

Anchor的用途
Anchor就是生成候选区的始祖,这些生成的Anchor里面有一些与Ground Truth比较“像”的将会被打上1的Label,表示我们希望生成这样的区域,而那些与Ground Truth几乎没有交集的Anchor,会被打上0的标签,这样以后又来了一个Anchor,我们就能给它打分:有多大概率他是一个标签为1(长得像GT)的Anchor,那么取分数前几名,我们就可以拿来作为RPN的输出了。
这里如何定义“像Ground Truth”呢?一个比较常用的方法是使用IoU,也就是两个框的重叠面积占总面积的比例

这里定义IoU:
在Faster-RCNN中,打标签的情况分为三种:
- 当生成的某个Anchor与任何一个GT的IoU大于0.7的话,这个Anchor将会被标注为正类(1类)
- 而如果他与任何一个GT的IoU都不大于0.3,我们把它标注为负类(0类)
- 对于每个Ground Truth,将与其IoU最大的Anchor也标记为1,这是为了保证每个Ground True至少都会有一个Anchor对应
除了这三类外,剩余的Anchor全部舍去,原因在于,这些模棱两可的图像比较容易混淆分类器。在实现中,我们可以把他们标注为-1,最后求loss的时候,忽略掉这些标签为-1的Anchor。然后投进网络进行训练Label,具体方法是,把上面生成的[N, M, C]的特征图中,每一个[1x1xC]的向量拿出来做FC,变成9x2维向量(2分类问题,每个位置对应着9个Anchor)通过Softmax和Cross Entropy形成loss回归,这里我们把这个loss叫做cls_pred_loss,即box分类loss。
这里需要注意的是,对所有的C维向量做FC需要先把特征图reshape成[NxM, C],然后乘以一个[C, 9*2]的权值矩阵然后再resize回来,这样的效果等效于使用1x1的卷积核进行卷积,卷积操作能够避免FC层维度固定的问题,这样让不同大小的图片输入称为可能。所以论文中使用了这种全卷积(FCN)的方法
Bounding Box回归
上面生成的Anchor无论数量多少(其实就是固定数量NxMx9)都是比较粗糙的,因为其固定位置,固定比例,也与图像本身特征没有任何关系,不管任何图像进来都是生成这些Anchor。可以想象,这些Box是比较死板的,为了使RPN生成的候选区更加准确,我们必须加入图像特征对anchor进行精修,这也就是BBox回归。
具体来看,BBox回归分为以下几个步骤:
- 将特征提取的出的特征图[N, M, C]使用上面全卷积的方法变为[N, M, 9x4]的Tensor9个候选Anchor,4代表了x,y,h,w的偏移$(t_x, t_y, t_h, t_w)$ 后面说 。
- 对于每一个Anchor,分配目标Ground Truth,然后计算与之的偏移作为target=$(t_x^, t_y^, t_h^, t_w^)$这里形状也是[N, M, 9*4]
- 把两个Tensor做loss,这里的loss比较奇特,是Fast-RCNN提出来的SmoothL1Loss,具体的下面说,暂且把它看成某种距离。
到此为止,BBox回归告一段落,以后来了N*M*9个的anchor,我们就能预测每个Anchor的4个偏移量shift,然后把这个偏移作用在这些anchor上形成最终的bbox。这里的loss我们叫做bbox_reg_loss,最终训练RPN的时候,最小化cls_pred_loss + bbox_reg_loss使得两者达到一个权衡,这也是深度学习中多目标问题的常用方法。
SmoothL1 Loss
上面没说完的就是这个SmoothL1Loss,其实很简单,只是一个平滑版的绝对值而已,在[-1, 1]的区间,这个loss被定义为L2 loss,剩余的其他地方被定义为L1 loss:
 (图引自网络)
(图引自网络)
公式上可以定义为:
为什么要使用SmoothL1Loss?
我们知道,在Fast RCNN的训练过程中,对Bounding Box的回归训练是重要的一个环节,一般来说,欧几里得距离(L2距离)就能应付这类回归数值问题,但是在bbox回归刚开始的训练的时候会有大量的噪声样本(因为背景类别千奇百怪,方差非常大)这些噪声样本在于真正的Ground Truth相减的时候,会产生比较大的误差,换句话说,上面那个公式的x的绝对值可能会非常大,所以如果直接使用$x^2$作为loss,在刚开始可能造成巨大的梯度,引发梯度爆炸问题,使训练动荡,难以收敛。所以在绝对值大于1的情况下,作者采用了L1loss。
其他细节
接下来填一下上面的几个坑:
- 每个Anchor的目标Ground Truth如何计算
现在有A个Anchor,G个Ground Truth计算两两之间的IoU形状为AxG,计算argmax得到A个最大值对应的Ground Truth就行了,但是这个速度是可想而知的,一般在VOC上,Anchor的数量能够达到几千个,而一张图中又有5~10个GT,这么算起来,求A和G的两两组合的box的计算量也不小。如果是python实现可能会非常慢,因此在实际的python版实现中,很多实用Cython对这个过程进行加速。
- 步骤二中的偏移$(t_x, t_y, t_h, t_w)$如何计算
在文章中写到,没有直接计算(x, y, h, w)的差值,而是使用了宽度和log变相的计算了一种偏移:
其中,$x, y$是预测框的中心坐标,$w, h$为预测框的宽和高,$x_a, y_a, w_a, h_a$是实际ground truth所对应的中心坐标和宽,高。注意这里,$t_x, t_y, t_w, t_h$才是真正学习的东西,也就是说,是网络输出的东西,而当测试的时候,我们将使用相反的式子获取到网络实际上预测的框,比如预测中心横坐标$x$的时候使用公式:
由于$x_a$是固定的,所以相当于是用tx做偏移,同理,在求w的时候也可以是使用:
来计算,这里,我们学习的$t_w$相当于是相对anchor宽的缩放。
代码实现如下:
def bbox_transform(ex_rois, gt_rois):
"""
computes the distance from ground-truth boxes to the given boxes, normed by their size
:param ex_rois: n * 4 numpy array, given boxes
:param gt_rois: n * 4 numpy array, ground-truth boxes
:return: deltas: n * 4 numpy array, ground-truth boxes
"""
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0
ex_ctr_x = ex_rois[:, 0] + 0.5 * ex_widths
ex_ctr_y = ex_rois[:, 1] + 0.5 * ex_heights
gt_widths = gt_rois[:, 2] - gt_rois[:, 0] + 1.0
gt_heights = gt_rois[:, 3] - gt_rois[:, 1] + 1.0
gt_ctr_x = gt_rois[:, 0] + 0.5 * gt_widths
gt_ctr_y = gt_rois[:, 1] + 0.5 * gt_heights
targets_dx = (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = np.log(gt_widths / ex_widths)
targets_dh = np.log(gt_heights / ex_heights)
targets = np.vstack(
(targets_dx, targets_dy, targets_dw, targets_dh)).transpose()
return targets
非极大值抑制(NMS)
参考博客 NMS——非极大值抑制-CSDN 非极大值抑制是排除候选框的一种常见方法,主要目的是对于多个重叠面积较大的候选框,留下score最大的候选框,其余的候选框都去掉。
假设所有预测框的集合为S,算法返回结果集合S’初始化为空集,具体算法如下:
(1)将所有框的得分降序排列,选中最高分及其对应的框(就是下图的0.98这个框,把这个框加入结果S’中)并把该框从S中删除

(2)遍历S中剩余的框,如果和当前最高分框(红色)的IoU大于一定阈值threshold,我们就将框从S中删除,其实就是把Rose脸的其他框去掉。

(3)从S未处理的框中继续选一个得分最高的加入到结果S‘中,重复上述过程(1, 2),开始处理Jack的脸。直至S集合空,此时S’即为所求结果。

NMS的Matlab代码在参考博客中有,这里贴一个python版的NMS,由于需要大量循环,所以还是需要使用Cython加速。
RPN的Inference
RPN训练完成以后,在测试的时候需要将图像通过特征提取网络,得到[N, M, C]的特征图,然后通过全卷积变成[N, M, 9x2]叫做cls_pred_score和[N, M, 9x4]的Tensor, bbox_pred,然后做以下操作
1. FOR (H, W) 的每个位置i:{
2. 生成一个中心位于i的Anchor
3. 使用bbox_pred反向作用于Anchor,得到pred_box
}
4. 去掉超出图像边界的pred_box
5. 过滤掉宽度或高度小于threshold的pred_box(非正常形状)
6. 按照预测分数从高到低排序
7. 在使用NMS之前选择分数TopN1的pred_box
8. 对剩余pred_box使用NMS
9. 在对NMS后余下的pred_box再取一次TopN2
10.返回pred_box作为Fast-RCNN的ROIPooling输入层的输入
RPN小结
到此为止RPN结构基本完成,主要的两个优化目标:
- 0、1的分类问题,本质上是Anchor的分类,训练目标是Anchor的标签
- BBox回归: 每个Anchor会有4个回归值作用于上一步分数较高的Anchor最后返回NMS的结果
4. Fast-RCNN
由于在RCNN和Faster-RCNN之间没有再写Fast-RCNN的笔记,因此在这里就一起总结Fast-RCNN的相关知识。因为Faster-RCNN的后半部分与Fast-RCNN完全一致
ROI Pooling
ROI Pooling是SPPNet中SPP层的特殊情况,当SPP特征层去掉Multi-Scale,然后把Pooling层的长宽固定下来,也就是ROI Pooling了。所以这里简单介绍SPP层的相关知识:
回顾一下RCNN慢的主要原因是什么? SS后的每个ROI区域(大约2000余个)都需要resize到固定大小,然后通过一次CNN提取特征。 有没有办法整张图像一次性通过CNN就能提取ROI的特征?
是有的,SPPnet提出,将整张图像通过一次CNN,然后把ROI的坐标映射到特征图上,在特征图上提取特征。这里有一个将原图上的坐标映射到特征图上的算法,后面填坑说。
但是问题就来了,即使能够将ROI映射到图上,那么这些特征的大小,比例也是不统一的(如下图)无法直接投入FC层训练
- 第一种方法:把这些特征都resize为统一大小,这种方法可能会造成特征的变形
- 第二种方法:设计一个不需要统一输入size,但是能够映射成统一size的操作:SPPnet

这里提到空间金字塔特征层,就是为了应对输入size不统一的输入而产生的。
首先分析一下,为什么需要固定的size?因为FC层的输入是固定的,那是不是去掉FC层就行了。OK,SPP层代替了FC层,他的做法是,将任意大小的输入图像分割成NxN个patch,然后对每个patch做pooling操作,得到一个NxN的行向量,这就统一了,可以输入FC层了(是的FC又回来了)
那么什么是金字塔呢?
金字塔是一个图像识别常常使用的一个Trick,说白了就是Multi-Scale,有时候金字塔是使用一张图像的多种分辨率,这里的做法是:对同一张图像,使用不同的N来做SPP提取,得到多个向量,然后Concat到一起,实验证明,Multiscale是非常有效果的。SPPnet的示意图如下:
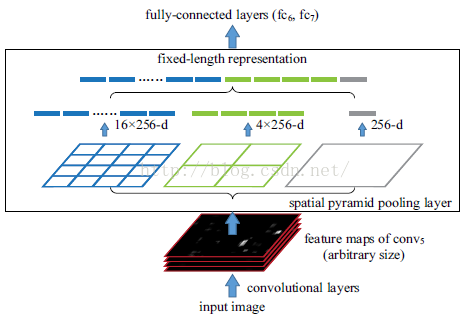
有了ROI Pooling这个结构以后,就可以从特征图上直接提取不同大小的候选框,然后导入FC层(当然也可以使用全卷积网络)这里的FC层有两个,一个是Softmax分类(C+1类,包括背景)和BBox回归:
- Softmax分类是一个多分类,用来分出这个提取的ROI含不含有object,如果含有,具体是哪一个object,所以需要C+1个类,C代表类别的数量
- BBox回归于RPN的BBox回归基本一样,也采用了算smoothl1损失
Fast-RCNN的训练
正负例的label如何标注:参考RCNN的标注方法,
- 训练的时候为了保证正例足够多,要求放宽,只需要与任何Ground True的IoU大于0.5即可把最大的Ground Truth类别标记为该Proposal的类别
- 回归BBox的时候要求数据要准确,所以需要把ground truth作为回归的对象
训练还是比较多Trick的,比如尽量保证正负例的平衡,困难样本挖掘(OHEM)等等。
Fast-RCNN的Inference
Fast-RCNN的前向过程也比较简单,每次测试一张图像,[1, 224, 224, 3]通过特征提取网络,直接得到一个14*14*512的特征图,然后结合ROI区域取出所有ROI区域对应的特征,把他们通过一个N*N的ROI Pooling层,得到一个[R, N*N]的Tensor通过两个FC层,变成[R, C+1]的分类结果和[R, 4]的BBox回归。
对于分类结果,首先执行NMS,去掉一些重复的框,留下分数最高的剩余的框根据分类结果是不是背景:
- 是背景:直接去掉
- 不是背景:把他的Label分配为最大的score,然后通过BBox回归结果反向作用在Anchor上生成最终的框位置
5. 总结
RCNN系列的结构比较复杂,在工程上也不太好实现,本篇笔记还有很多没有涉及的细节留待将来补充,这里仅对RCNN框架的基本思想进行总结。
目前深度学习在物体检测上的运用分为两大阵营:
- 以RCNN系列为基础的Region Proposal分类(two-stage)
- 准确率高
- 速度慢
- 实现复杂
- 以SSD为基础的end-to-end回归网络(one-stage)
- 准确率不如前者
- 速度快(YOLOv2和SSD都已经达到了实时性要求)
- 实现相对简单
接下来可能补充的点:
- ResNet作为骨架网络代替VGG的修改
- Faster-RCNN的一些训练Trick
- PyTorch版Faster-RCNN的源码分析
- NMS的Cython版和CUDA版源码分析
- Faster-RCNN中使用CUDA自定义PyTorch的ROIPooling层
- ROI Align,ROI Pooling,ROI Crop的区别