Welcome to Narcissus's Blog!
这里是Narcissus的技术圈-
二叉树
二叉树的下一个结点
/* struct TreeLinkNode { int val; struct TreeLinkNode *left; struct TreeLinkNode *right; struct TreeLinkNode *next; TreeLinkNode(int x) :val(x), left(NULL), right(NULL), next(NULL) { } }; */ class Solution { public: TreeLinkNode* GetNext(TreeLinkNode* pNode) { if (pNode == NULL)return NULL; TreeLinkNode*temp=NULL,*temp1=NULL; if (pNode->right != NULL) { temp = pNode->right; while (temp->left != NULL) { temp = temp->left; } return temp; } else if(pNode->next!=NULL)//因为给的可能是根节点,所以这里要判断下。 { temp= pNode->next,temp1 = pNode; while (temp != NULL&&temp->left != temp1)//注意判断条件 { temp1 = temp; temp = temp->next; } } return temp; } };思路注意这个题给了父节点的信息,所以不需要给二叉树的根节点信息,而当前节点可能是二叉树中的任一结点;分两种情况讨论:- 有右子树,则返回右子树的最左节点;
- 没有右子树:
- 没有父节点,返回NULL
- 有父节点,是该父节点的左儿子,则返回父节点;
- 有父节点,但是不是该父节点的左儿子,一直向上找,要注意判断条件:while (temp != NULL&&temp->left != temp1)
对称的二叉树
/* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) { } }; */ class Solution { public: bool isSymmetrical(TreeNode* pRoot) { if (pRoot == NULL)return true; return symmetrical(pRoot->left,pRoot->right); } bool symmetrical(TreeNode*left, TreeNode*right) { if ((!left) && (!right)) return true; if (!(left)||!(right))return false; return (left->val == right->val) && (symmetrical(left->left, right->right) && symmetrical(left->right, right->left)); }//左子树的左子树个右子树的右子树对称;左子树的右子树和右子树的左子树对称; };按Z字型顺序打印二叉树
/* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) { } }; */ class Solution { public: vector<vector<int> > Print(TreeNode* pRoot) { int depth = 0; vector<vector<int> > result; if (pRoot == NULL)return result; vector<TreeNode*>a; a.push_back(pRoot); print_level(a, depth, result); return result; } void print_level(vector<TreeNode*>a,int depth, vector<vector<int> >&result) { if (a.size() == 0)return; vector<int>level; vector<TreeNode*> temp; if (depth % 2 == 0) { for (int i = 0; i < a.size(); i++) { level.push_back(a[i]->val);//从前往后打印 //用新的vector<TreeNode*> temp来存下一层的指针 if (a[i]->left != NULL)temp.push_back(a[i]->left); if (a[i]->right != NULL)temp.push_back(a[i]->right); } } else { for (int i = a.size()-1; i>=0; i--)//从后往前打印 { level.push_back(a[i]->val); } for (int i = 0; i < a.size(); i++)//用新的vector<TreeNode*> temp来存下一层的指针 { if (a[i]->left != NULL)temp.push_back(a[i]->left); if (a[i]->right != NULL)temp.push_back(a[i]->right); } } depth++; result.push_back(level);//打印当前层结果 print_level(temp,depth,result);//迭代调用 } };思路按BFS的思路,但不同的是每一层迭代调用都用新的vector<TreeNode*> temp来存下一层的指针;
-
1.Two Sum
思路:这道题我写了两次代码,虽然题目简单,但是得考虑时空复杂度,否则不能全通过。为什么用python实现呢?因为想到可以用向量化计算nums=nums[:,None]+nums[None],然后再查找一次即可,结果空间复杂度太大,$O(n^2)$的复杂度,于是直接改循环了,但是for循环中j的变化不要从0开始,不然会重复计算导致时间复杂度太高。code:import numpy as np class Solution(object): def twoSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[int] """ # if len(nums)==0: # return [] # nums=np.array(nums) # nums=nums[:,None]+nums[None] # idx=np.eye(nums.shape[0])) # nums[idx[0],idx[1]]=target-1 # nums=np.where(nums==target) # if(nums[0].shape[0]==0): # return [] # return np.array(nums)[0].tolist() for i,val_i in enumerate(nums): j=i+1 for j in range(i+1,len(nums)): if (val_i+nums[j])==target:return [i,j] j+=1 return []
-
Word Embedding models VS. Distributed Semantic Models
若显示有问题,可查看pdf版
这篇文章主要讲了Word2Vec能够成功的一些因素,会和传统的分布式语义模型(DSMs)进行比较,并将一些技巧迁移到分布式模型上去,会显示出DSMs并不会比word2vec差,虽然这并不是新的见解,但由于这些传统方法在深度学习面前总是显得黯然失色,因此值得被再提及。这篇博客主要基于Improving Distributional Similarity with Lessons Learned from Word Embeddings 。
Glove模型
GloVe明确的做了SGNS(skip-gram with negative-sample)所含蓄表达的思想:将embedding 空间的向量偏移编码成语义信息。这在word2vec中是一个偶然的副产品,但却是Glove的目标。
Encoding meaning as vector offsets in an embedding space – seemingly only a serendipitous by-product of word2vec – is the specified goal of GloVe.
If we dive into the deduction procedure of the equations in GloVe, we will find the difference inherent in the intuition. GloVe observes that ratios of word-word co-occurrence probabilities have the potential for encoding some form of meaning. Take the example from StanfordNLP (Global Vectors for Word Representation), to consider the co-occurrence probabilities for target words ice and steam with various probe words from the vocabulary:
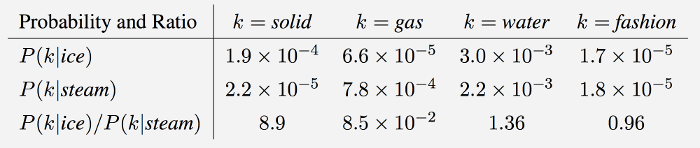
- “As one might expect, ice co-occurs more frequently with solid than it does with gas, whereas steam co-occurs more frequently with gas than it does with solid.
- Both words co-occur with their shared property water frequently, and both co-occur with the unrelated word fashion infrequently.
-
Only in the ratio of probabilities does noise from non-discriminative words like water and fashion cancel out, so that large values (much greater than 1) correlate well with properties specific to ice, and small values (much less than 1) correlate well with properties specific of steam. ”In this way, the ratio of probabilities encodes some crude form of meaning(粗糙的语义信息) associated with the abstract concept of thermodynamic phase. //第三行那个比例就包含的语义信息,比如k=solid的时候,$p(k ice)/p(k stream)$的值很大,说明ice更多的是和solid相关的,而stream则不太跟固体相关,这里就包含了一些热力学里面的语义信息。
However, Word2Vec works on the pure co-occurrence probabilities so that the probability that the words surrounding the target word to be the context is maximized..
-
论文阅读 Phrase Localization and visual relationship detection with comprehensive Image-language cues
- 1.文章思想
- 2.文章用了多种组合的特征:
- 3.从sentence 解析 phrases
- 4.损失函数的构建
- 5.同时进行多个phrase location的过程(测试过程)
- 6.关系检测任务
- 7.VRD实验结果
这篇文章主要是对phrase location(就是说输入图像和image caption来定位objects)来做的,后面又应用这个来做了一个关系检测的实验,我觉得这很可能是在后期做的一个补充。检测结果相对于前面看的几篇文章都要好。他这个创新点,主要是用了多种cues,并自己设计了有效的损失函数等,phrase lacation这里没有细看。
用了字幕数据,通过nlp进行parse sentence,phrase的解析得到entities、relationships、以及一些其他的linguistic cues。
1.文章思想
输入image和caption,用nlp tools处理代指关系,提取caption中的noun phrase和pair of entities。并做以下处理:
- 1)对于noun phrase(如red umbrella),根据appearance、size、position、attributes(形容词)等来为每一个候选的box计算一个single-phrase cue scores;
- 2)对于pair of entities(man carries a baby),则通过spatial model来对相应的candidate boxes计算score;
- 3)对于actio类的phrase,建立一个subject-verb和verb-object的 appearance models;
- 4)对于people、clothing、body parts之间的关系,phrase通常用来描述individuals,而且也是现有方法比较难定位其中的物体,因此对于这种phrase常常给与spetial treatment。

2.文章用了多种组合的特征:
现有的一些工作要么只定位那些attribute phrase中的物体,要么只解决了possessive pronouns 等代指的关系,而本文:
- 1)we use pronoun cues to the full extent by performing pronominal coreference ;
- 2)ours is the only work in this area incorporating the visual aspect of verbs.
- 3) with a larger set of cues, learned combination weights, and a global optimization method for simultaneously localizing all the phrases in a sentence (就是说能同时解决一个sentence中的所有phrases)

3.从sentence 解析 phrases
linguistic cues corresponding to adjectives, verbs, and prepositions must be extracted from the captions using NLP tools. hey will be translated into visually relevant constraints for grounding. And we will learn specialized detectors for adjectives, subject-verb, and verb-object relationships ,we will train classifiers to score
pairs of boxes based on spatial information 。
这个部分就是根据nlp提取一些形容词、动词、entities、relationships等language cues,具体的有点感觉,考虑了多种特殊的情况。
4.损失函数的构建
single phrase cues (SPC) measure the compatibility of a given phrase with a candidate bounding box, and phrase pair cues (PPC) ensure that pairs of related phrases are localized in a spatially coherent manner
-
single phrase cues
-
phrase-pair cues
5.同时进行多个phrase location的过程(测试过程)
6.关系检测任务
这个模型扩展到VRD任务上去,能有较好的zero-shot detection的作用。
用了以下几个CCA 模型,用的是fast rcnn在MSCOCO上面训练的模型:

7.VRD实验结果

-
论文阅读:Object Detection Using Scene-Level Context and Instance-Level Relationships
SIN网络结构

网络结构解释
首先对输入图像利用faster-rcnn进行物体检测,得到一些ROIs,对ROI进行ROI pooling得到固定size的feature map,再经过全连接层映射成一些节点(nodes,即feature vector),并两两组合得到edges,即得到object relationship context。对整个图像提取特征得到scene context。将两种context送入到GRU(选择GRU的原因是其具有记忆功能,能融合来自多方面的context,并传递到下一次更新中,即有消息传递功能),这个GRU的原理如下:

这里r开关和z开关的详细定义及作用可看论文
全局context与局部context
对于每一个物体的定位,它利用了来自scene GRU的信息和Edge GRU的信息,如下:

形式化的表示为:

其中的空间位置特征表示为:

最后得到隐藏层t+1的特征表示(通过mean pooling 得到):

结果分析
-
量化结果是一个总体结果,肯定是好的,这个需要跑代码看,数据是否对。
-
qualitative results
Scene module结果中比较值得一说的是failure case:将海里的airoplain识别成了boat,说明对这种罕见的场景来说scene context是不好的

- Edge module的结果:定位错误的结果减少;能够减少重复检测的结果:


- 结合两种context的结果:

题注
-
-
循环神经网络的梯度消失及梯度爆炸问题
RNN的梯度消失、爆炸问题
- RNN原理、公式推导及python实现
- Word Embedding models的深入理解
- 从EncoderDecoder到Transformer
- 十大排序算法(一)-堆排序
- [转]论文阅读:Semi-Supervised Classification with Graph Convolutional Networks
- graph convolutional network思想简介
- 0/1背包问题
- 自平衡二叉搜索树
- relation network for object detection
- Deep Visual-Semantic Alignments for Generating Image Description